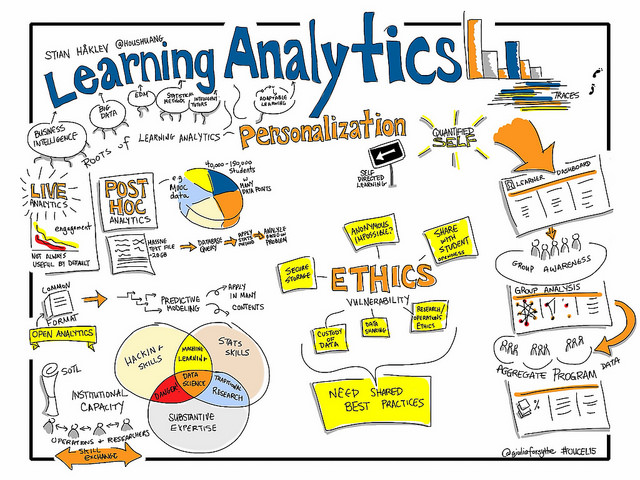
Le développement du big data traverse l’ensemble des secteurs de notre société y compris les universités. En effet, le milieu universitaire est également confronté à une production exponentielle de données réalisée dans le cadre de la recherche, c’est évident, mais aussi par les étudiants. Un article de l’Université de l’Arizona publié en début d’année rappelait combien les étudiants étaient scrutés notamment à travers l’utilisation de leur carte étudiante. L’objectif de l’université était de pouvoir prédire quels sont les étudiants qui abandonneront leurs études en cours d’année ou de cursus. Qui dit étudiant, dit aussi bibliothèque universitaire. Les BU pourraient être tentées de céder « à la mesure, la collecte, l’analyse et la présentation de rapports basés sur des données des apprenants en contexte d’apprentissage » (source), autrement dit aux méthodes de Learning Analytics.
La question des menaces des méthodes de learning analytics sur la vie privée n’est pas nouveau. Lionel Maurel a d’ailleurs écrit un très bon article à ce sujet l’an dernier. L’Amercan Libraries Magazine vient de publier un article sur cette thématique. L’analyse de l’apprentissage peut présenter des avantages et être utilisé à bon escient. Ces méthodes peuvent être l’occasion d’améliorer l’apprentissage des apprenants et aider à comprendre les difficultés que peuvent rencontrer des personnes en situation d’apprentissage. Ces techniques d’analyse de données sont aussi l’occasion de pouvoir améliorer des plateformes d’apprentissage comme le rapportait la CNIL
« Ces plateformes permettraient en outre d’optimiser le coût des formations, de personnaliser les cursus et idéalement de motiver les étudiants, en leur apportant des retours sur les apprentissages »
Au-delà des dérives potentielles, il existe un argument non-négligeables qui peut justifier cette analyse approfondie du comportement des étudiants et qui est lié à la question du budget. Un professeur du Wisconsin soulignait à juste titre que « quand des personnes défendent des budgets, elles doivent ensuite prouver que les crédits obtenus ont été utilisés intelligemment. Et un des moyens d’y parvenir est de s’appuyer sur les données d’utilisation. »
Mais il y a aussi des risques notamment sur la vie privée des étudiants et potentiellement sur la liberté d’expression. Deborah Caldwell-Stone, de l’American Library Association, explique que la surveillance à outrance y compris de l’usage qui est fait de la bibliothèque par un étudiant a des conséquences sur la liberté d’expression dans la mesure où une personne qui se sait surveillée à tendance à s’auto-censurer pour éviter de révéler des choses sur elle. Par ailleurs, cette surveillance est parfois réalisée à l’insu des étudiants qui ne mesurent pas que l’accès à telle ressource électronique, le temps passé sur tel article ou le téléchargement d’un livre électronique est consciencieusement collecté. Par conséquent, si l’étudiant n’a pas connaissance de ces techniques d’analyse d’apprentissage, il n’a pas la possibilité d’exercer son opposition à ce traitement de données. En outre, l’analyse d’apprentissage suppose, comme pour tout traitement de données, une sécurisation des données collectées qui pourraient être utilisées à des fins qui ne correspondent pas aux finalités initiales du traitement. Ou bien elles pourraient être utilisées par un prestataire sur lequel l’établissement n’a aucun contrôle.
Pour prévenir toute utilisation abusive des données, les bibliothécaires mutent et se transforment en library applications et system manager à l’image de la bibliothèque de Seattle. L’objectif de ces bibliothécaires élevés en plein air et nourris au big data et de s’assurer que la collecte de données respecte la vie privée des utilisateurs. Becky Yoose est une de ces bibliothécaires et propose des méthodes pour empêcher de ré-identifier un individu à partir des données collectées. Cela implique bien évidemment un degré de sophistication important de l’infrastructure technique de traitement des données. Par exemple, l’entrepôt de données de la bibliothèque ne collecte pas la date d’anniversaire d’un utilisateur mais uniquement l’âge au moment de l’emprunt. De même, le système ne va pas stocker le numéro complet du document mais une version tronquée qui permet d’identifier la catégorie du document mais pas son titre précis. Par ailleurs, il faut savoir qu’il faut très peu de données pour pouvoir ré-identifier une personne :
« Aux Etats-Unis, il a ainsi été révélé que les bases de données commerciales permettent d’identifier 87% des Américains rien qu’avec leur date de naissance, leur sexe et leur code postal. En d’autres termes, avec les techniques de recoupement de données venant de base de données différentes il devient de plus en plus difficile de rester anonymes. » (L’ empire des données : essai sur la société, les algorithmes et la loi / Adrien Basdevant, Jean-Pierre Mignard)
Les menaces sur la vie privée liées aux learning analytics reposent aussi sur le volume d’utilisateurs. Plus il y a d’usagers, plus il est difficile de retrouver une personne en croisant les données. Mais le risque est toujours présent. Toujours d’après Becky Yoose, dans une BU, l’année d’un étudiant et une matière suffisent à identifier la personne. Et bien évidemment plus on recueille de données, plus le risque de ré-identification est fort. La responsable de la vie privée de l’Université de Berkley a produit une grille de questions qu’il convient de se poser afin de réduire les risques :
Degré de transparence et de prédictabilité : dans quelle mesure les personnes sont-elles informées sur l’objet de la collecte de données et l’utilisation qui en sera faite ?
Degré d’anonymité et de choix : dans quelle mesure les données sont-elles rendues anonymes, ou la personne a-t-elle le choix de participer ?
Degré d’accès, de propriété et de contrôle : quel est le niveau d’accès et de propriété des données pour les individus, les institutions, les vendeurs de prestations et le public ?
Responsabilité en matière d’utilisation éthique, de gérance et de gouvernance : quels principes éthiques et quelles mesures de responsabilisation les entités qui manipulent les données des étudiant·e·s démontrent-elles ?
Quels sont les standards de sécurité et techniques mis en oeuvre ?
L’autre écueil est de croire que les données collectées sont suffisamment sécurisées. C’est ce qu’explique Kristin Briney, data services librarian à l’Université du Wisconsin, qui observe un manque de rigueur ou des procédures qui ne sont pas adaptées. Dans ce contexte, Briney participe à Data Doubles un projet financé par l’Institue Museum and Library Services qui consiste à mesurer l’impact sur les étudiants de l’utilisation de leurs données par les universités et les bibliothèques. Ce serait intéressant de construire un projet similaire en France.
Source : American Libraries Magazine